Replanification spatialement référencée
Qu’est-ce que la replanification ?
La replanification est un processus qui consiste à resolutioner un modèle d’optimisation de coupes forestières (comme ceux utilisés dans FMT) pour prendre en compte des éléments qui ne peuvent pas être considérés dans le processus classique de résolution de ces modèles d’optimisation.
La replanification permet donc de se poser des questions plus complexes; en particulier, elle permet de toucher aux interactions entre les différents niveaux de la planification hiérarchique en foresterie (stratégique, tactique et opérationnel).
Voici quelques exemples de questions auxquelles la replanification permet de répondre :
- Des questions liées aux effets des perturbations naturelles (feux, tordeuse des bourgeons de l’épinette, etc.)
- Quel est l’effet des feux à long terme sur les niveaux de récolte déterminés par le niveau stratégique ?
- Quel est l’effet d’un changement de régime d’une perturbation stochastique (aléatoire) sur les niveaux de récolte déterminés par le niveau stratégique ?
- Des questions liés aux incohérences entre ce qui est prévu au niveau stratégique (à grande échelle), et la réalité du terrain (à petite échelle) : c’est la notion de drift entre les différents niveaux de l’aménagement hiérarchique
- Est-ce que les objectifs sont toujours atteints en prenant en compte des problématiques et des contraintes plus précises au niveau tactique ?
- Des questions liées aux interactions entre les niveaux stratégique et tactique
- Quel est l’effet de communiquer (ou non) certaines informations au modèle tactique ou stratégique ? Qu’est-ce qui change ? Qu’est-ce qui ne change pas ?
La replanification spatialement référencée en pratique
Les modèles utilisés
Lorsqu’on utilise FMT, la replanification spatialement référencée se fait en pratique à l’aide de trois modèles de FMT.
Ces trois modèles représentent trois scénarios appliqués à un même paysage initial(mêmes sections AREA, CONSTANTS, LANDSCAPE, OUTPUTS). Cependant, ces scénarios peuvent avoir des éléments différents les uns des autres (sections ACTIONS, TRANSITIONS, YIELDS et OPTIMIZE différentes).
Ces trois modèles sont :
1. Le modèle stratégique
C’est un modèle de programmation linéaire de type III, comme décrit dans les bases de FMT.
C’est ce modèle qui va représenter ce qui se passe au niveau stratégique, c’est-à-dire quand on regarde les choses d’en haut sans prendre en compte certains détails à des échelles plus fines.
2. Le modèle stochastique
C’est un modèle de simulation non-spatial (qui fonctionne dans un espace spatialement référencé comme les modèles linéaires, et non pas spatialement explicite).
Il va servir à simuler des actions pseudo-aléatoires avec des cibles de superficies à atteindre. Ces actions peuvent représenter des feux de forêts, des épidémies d’insectes, et bien d’autres encore !
3. Le modèle tactique
Comme le modèle stratégique, c’est un modèle de programmation linéaire de type III, comme décrit dans les bases de FMT.
Ce modèle va servir à refaire une optimisation de la planification forestière tout en prenant en compte les changements que le modèle stochastique à pu effectuer sur le paysage, ou bien avec des contraintes différentes ou supplémentaires par rapport au modèle stratégique.
L’exemple d’une itération de replanification
La replanification se fait à l’aide des trois modèles décrits précédemment, en les appelant les un après les autres au sein de chaque période de replanification. Comme l’un des modèles (le modèle stochastique) contient des événements aléatoires, il est cependant possible de refaire tout le processus plusieurs fois afin de prendre en compte la variabilité liée à ces événements aléatoires : c’est ce que l’on appelle une itération.
Lorsqu’on appelle les modèles les un après les autres, certaines de leur caractéristiques sont passées de l’un à l’autre (inventaire/état du paysage pour la période, ou bien contraintes et planification existante).
Au final, une itération de replanification prend la forme suivante :
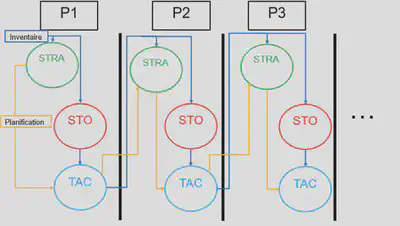
Dans ce schéma,
- STRA correspond au modèle stratégique
- STO correspond au modèle stochastique
- TAC correspond au modèle tactique
On peut ainsi voir que pour chaque période,
- Le modèle stratégique est appelé pour faire sa planification
- La planification du modèle stratégique se fait sur un horizon long; et cet horizon ne change pas à travers les périodes. C’est-à-dire qu’à chaque période, le modèle stratégique va, par exemple, planifier pour les 100 ans à venir; que ce soit 100 ans après la période 1, ou 100 ans après la période 3.
- Le modèle stratégique partage le même inventaire que le modèle stochastique, ce dernier est appelé à faire sa simulation pour introduire des différences avec l’inventaire qui sera passée au modèle tactique.
- Le modèle stochastique ne va faire cette simulation que pour la période de temps donnée (contrairement au modèle de planification qui va faire son optimisation en prenant en compte le long terme). C’est parce que le modèle stochastique ne fait que simuler des événements aléatoires, et ne cherche pas à optimiser quoi que ce soit.
- L’inventaire résultant du modèle stochastique va être passé au modèle tactique, qui est appelé pour faire sa replanification
- Le modèle tactique ne va planifier que sur la période donnée; il ne va pas simuler le long-terme comme le modèle stratégique, même s’il essaye de faire une optimisation. Son objectif sera, par exemple, de récolter du bois sans dépasser la quantité de bois récoltée par le modèle stratégique, mais en prenant en compte l’inventaire modifié par les événements aléatoires du modèle stochastique.
- L’inventaire résultant du modèle tactique est ensuite repassé au modèle stratégique, qui va ensuite planifier à nouveau pour la période suivante.
On peut ainsi voir deux vas-et-viens entre les modèles :
- Le passage de l’inventaire d’un modèle à un autre au fur et à mesure du processus (lignes bleues sur le schéma)
- Le passage de contraintes de planification du modèle stratégique au modèle tactique (lignes jaunes sur le schéma)
Notez bien que tout ce processus ne représente qu’une seule itération de la replanification. Afin de réellement prendre en compte les effets des évenements stochastiques, il est important de répéter tout ce processus de nombreuses fois. Cela permet de prendre en compte la variabilité qui existera dans la manière dont l’inventaire et le modèle tactique vont réagir aux événements aléatoires; le modèle tactique peut aussi contenir des composantes aléatoires en son sein.
Les modèles de replanification en détail
Le modèle stratégique
- C’est un modèle d’optimisation par programmation linéaire (
FMTlpmodel).- Il ne prend pas en compte les perturbations naturelles ou les événements stochastiques.
- Normalement, il a un horizon de planification long pour faire le suivi de variables et optimiser certains éléments sur le long terme (e.g. 100 à 150 ans).
- Il dicte la voie à prendre au modèle tactique en lui transmettant des informations.
- Il peut utiliser le nouveau mot clé
_SETFROMLOCAL(ratio).
Le modèle stochastique
- C’est un modèle de simulation non-spatial (
FMTnssmodel).- Il simule des perturbations naturelles ou des événements stochastiques.
- Il peut posséder un horizon de simulation long; mais il ne simule qu’une période à la fois.
- Son rôle est d’affecter le territoire utilisé par le modèle tactique, et donc de brouiller les cartes entre le modèle stratégique et le modèle tactique.
- Il peut utiliser les nouveaux mots clés
_RANDOM(output)et_REPLICATE(output).
Le modèle tactique
- C’est un modèle d’optimisation par programmation linéaire (
FMTlpmodel), comme le modèle stratégique. - Son horizon de planification est de seulement une période.
- Car à l’échelle tactique, on ne prend en compte que le court-terme, et non le long-terme.
- Son état initial est celui de la période actuelle, donné par le modèle stochastique.
- Il peut utiliser les nouveaux mots clés
_SETFROMGLOBAL(ratio)et_SETGLOBALSCHEDULE(ratio).
Les nouveaux mots-clés associés à la replanification
Différents mots clés qui n’existent pas dans la syntaxe Woodstock permettent d’implémenter des va-et-vient d’information entre les différents modèles de la replanification, selon le schéma suivant :

D’autres permettent d’ignorer des contraintes à des moments donnés, ou bien de les ajuster.
Vous trouverez ici la liste de ces nouveaux mots-clés liés à la replanification :
_REIGNORE(period)
Ce mot clé doit apparaître dans la section OPTIMIZE d’un modèle.
Il permet d’indiquer au modèle d’ignorer une contrainte à partir d’une période de replanification précise.
Ceci peut être très utile pour instaurer une période de mise à jour de la planification, et ensuite ignorer les contraintes qui y sont liées.
_REPLICATE(fichier.csv)
Ce mot clé permet de venir changer le terme à droite de l’équation (Right Hand Side, ou RHS) d’une contrainte en venant chercher une valeur dans un tableau contenant ces valeurs pour différents réplicas.
En pratique, on peu déposer un fichier .csv dans le répertoire du scénario, puis utiliser _REPLICATE(fichier.csv) pour que FMT applique une certaine valeur dans ce tableau pour l’itération à laquelle il se trouve.
Par exemple, écrire la chose suivante dans la section des contraintes d’un modèle :
_RANDOM(outputaction) <= 10 1 _REPLICATE(fichier.csv)
permet de remplacer, à chaque itération, le chiffre “10” de la contrainte par le chiffre de la ligne 1 du fichier fichier.csv avec la colonne qui correspond à l’itération.
Dans le fichier, les lignes correspondent donc à la période et les colonnes à l’itération à laquelle on veut que la valeur s’applique.
_SETFROMLOCAL(ratio)
Ce mot clé permet au modèle stratégique d’ajuster une de ses contraintes en fonction de la valeur du output correspondant dans le modèle tactique utilisé à la période précédente.
Avec cette contrainte, on précise un ratio qui peut augmenter ou diminuer la valeur prise du modèle tactique. Par exemple, un ratio de 1.0 donnera exactement la valeur du modèle tactique; un ratio de 2.0 va la multiplier par deux, et un ratio de 0.5 la divisera par deux.
Si on écrit la chose suivante dans la section des contraintes d’un modèle stratégique :
VOLUMEREC <= 0 1.._LENGTH _SETFROMLOCAL(1)
on se trouve à remplacer systématiquement le chiffre “0” du RHS par la valeur du output VOLUMEREC de la période de replanification précédente du modèle tactique.
_RANDOM(output)
Ce mot clé est utilisé pour générer des valeurs de façon aléatoire pour le modèle stochastique.
_RANDOM(output) doit être un output d’action, et non un output d’inventaire.
Il s’écrit comme pour une contrainte standard.
Voici un exemple pour générer un chiffre aléatoire entre 50 et 100 pour les périodes 1 à LENGTH :
_RANDOM(outputaction) <= 50 1.._LENGTH
_RANDOM(outputaction) >= 100 1.._LENGTH
_SETFROMGLOBAL(ratio)
Ce mot-clé est utilisé pour ajuster une contrainte du modèle tactique basé sur une valeur déterminée par le modèle stratégique. C’est un peu la réciproque de _SETFROMLOCAL(ratio).
Le ratio permet d’augmenter ou de diminuer la valeur prise du modèle stratégique. Par exemple, un ratio de 1.0 donnera exactement la valeur du modèle stratégique; un ratio de 2.0 va la multiplier par deux, et un ratio de 0.5 la divisera par deux.
Si on écrit la chose suivante dans la section des contraintes d’un modèle tactique :
VOLUMEREC <= 0 1.._LENGTH _SETFROMGLOBAL(1)
on remplace systématiquement le chiffre “0” du RHS par la valeur du output VOLUMEREC du modèle stratégique pour la période de replanification en cours.
_SETGLOBALSCHEDULE(ratio)
Ce mot clé permet d’inclure la solution (ce qui a été planifié comme actions) du modèle stratégique dans le modèle tactique sous forme de poids à la fonction objective.
Pour ce faire, lors de l’évaluation de la solution du modèle tactique, à chaque fois que ce dernier planifiera une action sur un même développement que prévu au modèle stratégique, il multipliera la superficie planifiée (au niveau tactique) par le ratio spécifié et ajoutera la valeur à l’objectif selon la formulation de la fonction objective. Si le modèle doit maximiser, on additionnera et s’il doit minimiser, on soustraiera la valeur calculée.
Les résultats de la replanification
Suite au processus de replanification, on obtient les résultats suivants :
- Trois fichiers de résultats bruts (un par modèle)
- Un fichier de probabilités (un seul pour tout le processus)
Les fichiers de résultats bruts par modèles
Ces fichiers contiennent des valeurs liées aux outputs dans les différents modèles, pour les différentes périodes, et pour les différentes itérations.
Ils contiennent différentes colonnes :
Iteration: Indique le numéro de l’itération qui est fait pour prendre en compte de la stochasticité. L’itération “0” concerne le modèle stratégique “de base”, qui est résolu au tout début du processus de replanification.Period: Indique la période de replanification qui concerne la valeur de l’output.Output: Nom de l’output considéré.Value: Valeur du output considéré.Type: Type de output (indique si c’est un output “total” pour tout le paysage, ou par développement/peuplement).
Le fichier de probabilités
Ce fichier contient les probabilités que des outputs du modèle tactique puissent s’éloigner (drift) de la solution du modèle stratégique initial (résolu au tout début du processus de replanification), dont les outputs se trouvent dans l’itération “0” des fichiers de résultats bruts.
Pour chacun des outputs définis dans les modèles, le fichier de probabilité contiendra toutes les probabilités de rester dans l’intervalle inférieur et supérieur du ratio d’éloignement (drift) vis-à-vis des outputs du modèle stratégique initial, pour les valeurs de ratio d’éloignement suivantes : 0, 0.05, 0.10, 0.15, 0.20, 0.25, 0.30, 0.35, 0.40, 0.45, 0.50.
Ce fichier contient différentes colonnes :
Period: Indique la période de replanification qui concerne la valeur de l’output.Output: Nom de l’output considéré.LowerProbability: Probabilité de rester dans l’intervalle inférieure du ratio d’éloignement.UpperProbability: Probabilité de rester dans l’intervalle supérieure du ratio d’éloignement.Drift: Ratio d’éloignement entre la solution du modèle tactique et celle du modèle stratégique initial.
Pour comprendre les probabilités, il faut d’abord regarder le ratio d’éloignement, la valeur du modèle stratégique initial, puis les probabilités.
Par exemple :
- Si la valeur du modèle stratégique initial pour un output donné est de 1000.
- Et si, pour la période 1, on obtient une
LowerProbabilityde 1 et uneUpperProbabilityde 1 pour un drift de 0.3.- Alors, cela veut dire qu’il y a une probabilité de 100% pour que l’output reste entre une valeur de 700 et de 1300 pour la période 1.
- Et si, pour la période 10, on obtient une
LowerProbabilityde 0.6 et uneUpperProbabilityde 0.4 pour un drift de 0.5.- Alors, cela veut dire qu’il y a une probabilité de 60% que l’output reste au dessus de 500, et une probabilité de 40% qu’il reste en dessous de 1500 à la période 10.