Planification forestière à l’aide du Machine Learning

Problématique
- Notre bilan carbone est difficile à obtenir rapidement
- Pour tous les réservoirs de l’écosystème
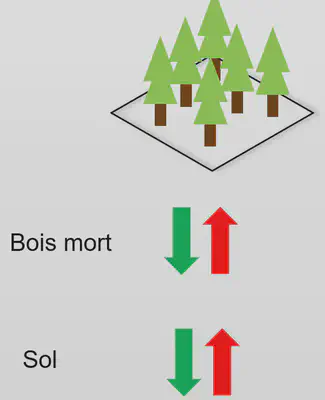
- Carbone du sol
- Biomasse souterraine
- Litière
- Bois mort
- Biomasse aérienne
- Pour la productivité nette de l’écosystème
- Pour tous les réservoirs de l’écosystème
Problématique
- La localisation des activités sylvicoles pouvant améliorer le bilan carbone est un enjeu complexe
- Le calcul du bilan de carbone forestier pour un modèle de planification est complexe
- L’optimisation spatialement explicite de la localisation des travaux sylvicoles peut être très difficile à réaliser avec un modèle mathématique classique
Productivité nette de l’écosystème
Productivité nette de l’écosystème
Problématique: Productivité nette de l’écosystème ?
Problématique: État des réservoirs ?
Problématique: État des réservoirs ?
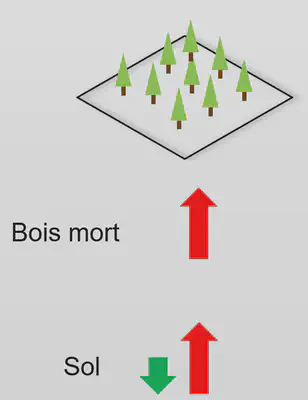
Problématique: État des réservoirs ?
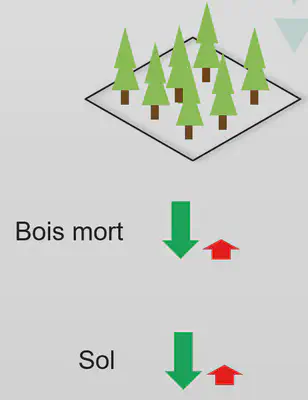
Problématique:…Pour chaque période
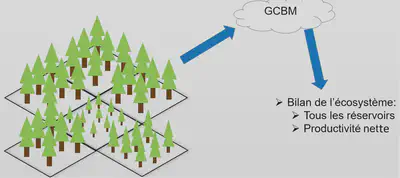
Objectif
- Obtention du bilan de carbone rapidement
- Tous les réservoirs de l’écosystème
- Carbone du sol
- Biomasse souterraine
- Litière
- Bois mort
- Biomasse aérienne
- La productivité nette de l’écosystème
- Tous les réservoirs de l’écosystème
Données d’apprentissage
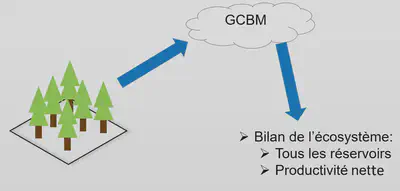
Apprentissage réalisé
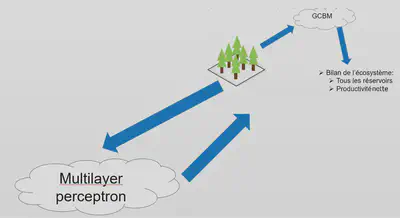
Utilisation de la méthode

Utilisation de la méthode
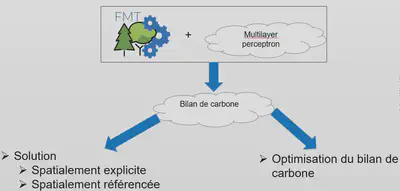
Concrètement
- Nouvelle syntaxe pour la section yield
- Voir dans examples/Models/TWD_land/Scenarios/Predictors
- Développement d’un nouveau type de yield “*YM”
Modèle pour les réservoirs
{
Intrants:
- GFI = Volume de feuillus intolérants
- GFT = Volume de feuillus tolérants
- GF = Volume feuillu total
- GR = Volume résineux total
}
*YM ? ? ?
AG_Biomass_C,BG_Biomass_C,Deadwood_C,Litter_C,Soil_C _PRED(pools_carbon,GFI,GFT,GF,GR)
{
Extrants:
- AG_Biomass_C = Biomasse aérienne
- BG_Biomass_C = Biomasse souterraine
- Deadwood_C = Bois mort
- Litter_C = Littière
- Soil_C = Sol
}
Modèle pour la productivité nette de l’écosystème
{
Intrants:
- GFI = Volume de feuillus intolérants
- GFT = Volume de feuillus tolérants
- GF = Volume feuillu total
- GR = Volume résineux total
}
*YM ? ? ?
NEP _PRED(nep_carbon,GFI,GFT,GF,GR)
{
Extrants:
- AG_Biomass_C = Biomasse aérienne
- BG_Biomass_C = Biomasse souterraine
- Deadwood_C = Bois mort
- Litter_C = Littière
- Soil_C = Sol
}
Suivi des variables
;Inventaire de la productivité nette de l'écosystème en (c)
*OUTPUT NEP_Total
*SOURCE ? ? ? _INVENT NEP
;Inventaire de la biomasse aérienne et souterraine en (c)
*OUTPUT Biomasse_Total
*SOURCE ? ? ? _INVENT AG_Biomass_C + ? ? ? _INVENT BG_Biomass_C
;Inventaire du carbone du sol en (c)
*OUTPUT Sols_Total
*SOURCE ? ? ? _INVENT Soil_C
Problématique : Optimisation spatialement explicite
- Pratiquement impossible avec nos modèles
- Utilisation d’une heuristique pour placer la récolte
- Difficile à obtenir à moins d’implémenter une heuristique:
- Simulated Annealing
- Tabou Search
- Utilisation de la programmation mixte intégrale
- On peut donc difficilement répondre à la question du où doit t’on faire tel ou tel traitement pour améliorer notre bilan de carbone
Objectif : Meilleur bilan
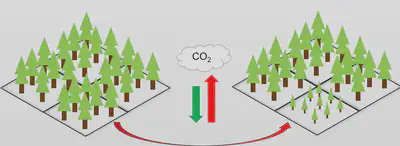
Objectif : Meilleur bilan
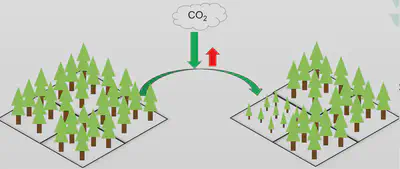
Objectif : Meilleur bilan et respect des contraintes
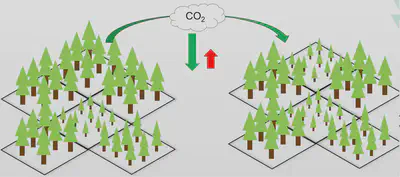
Objectif : Meilleur bilan et respect des contraintes
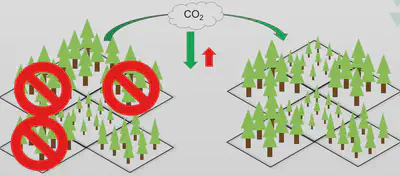
Apprentissage
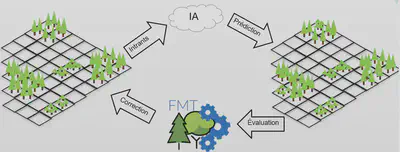
Apprentissage
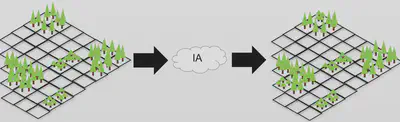
Conclusion
-
On peut maintenant obtenir un bilan de carbone facilement pour:
- Une solution spatiale explicite et spatialement référencée
- Les cinqs principaux réservoirs de l’écosystème
- Le flux de productivité nette de l’écosystème
-
On peut maintenant utiliser le Machine Learning pour:
- Générer des solutions spatialement explicites plausibles
- Améliorer notre planification en fonction de notre bilan de carbone
Des Questions?