Planification forestière à l’aide du Machine Learning (Mise à jour 2023)

Les problématiques
- Notre bilan carbone est difficile à obtenir rapidement
- Pour tous les réservoirs de l’écosystème
- Pour la productivité nette de l’écosystème
- La localisation des activités sylvicoles pouvant améliorer le bilan carbone est un enjeu complexe
- Le calcul du bilan de carbone forestier pour un modèle de planification est complexe
- L’optimisation spatialement explicite de la localisation des travaux sylvicoles peut être très difficile à réaliser avec un modèle mathématique classique
Les objectifs
- Obtention du bilan de carbone rapidement (Article #1)
- Tous les réservoirs de l’écosystème
- La productivité nette de l’écosystème
Bilan carbone avec l’IA
stateDiagram
direction LR
state IA_par_pixel {
direction LR
state Intrants {
direction LR
Dernières_perturbations
Volume_de_feuillus_tolérants
Volume_de_feuillus_intolérants
Volume_de_résineux
}
Intrants --> Réservoir
state Réservoir {
Biomasse_aérienne
Biomasse_souterraine
Bois_mort
Carbone_du_sol
Litière
}
Intrants --> Flux
State Flux {
Productivité_nette_de_l'écosystème
}
}
IA_par_pixel --> Entrainement
State Entrainement {
direction LR
CPF2328 --> Global
CPF2328 --> Pessière
CPF2328 --> Sapinière
CPF2328 --> Érablière
}
Entrainement --> Validation
State Validation {
direction LR
Spatial --> 07152
Non_Spatial --> 07152
Spatial --> 02751
Non_Spatial --> 02751
Spatial --> 08665
Non_Spatial --> 08665
Spatial --> 08762
Non_Spatial --> 08762
Spatial --> 09751
Non_Spatial --> 09751
}
Les objectifs
- Génération de planification spatialement explicite (Article #2)
- Maximisant le bilan carbone
Planification spatiale par IA
stateDiagram
direction LR
Modèle --> FMTsamodel
state FMTsamodel {
direction LR
state Intrants {
direction LR
(i)Cellule --> Âge
(i)Cellule --> Opérabilité
(i)Globale --> Taille_des_blocs
(i)Globale --> Délai_dadjacence
}
Intrants --> IA
state Générateur {
direction LR
Calcul_2328 --> Apprentisage
}
State IA {
Générateur --> Prédiction
state Prédiction {
(o)Spatiaux --> Blocs_de_coupes
(o)Non_spatiaux --> faisabilité
(o)Non_spatiaux --> Bilan_carbone
}
}
IA --> Optimisation
State Optimisation {
Validation --> Amélioration
}
}
FMTsamodel --> Solution
gantt
dateFormat YYYY-MM-DD
title Projet FORAC
excludes weekends
section IA estimateur carbone
Script d'entrainement :done,des1,2021-04-01,2021-09-01
Script d'utilisation : done,des2,2021-04-01,2021-09-01
Sélection du modèle : done,des2,2021-04-01,2021-05-01
Rapport : done,des3,2021-09-01,2021-10-01
Installation FMT release :done,des4,2021-10-01,2021-11-01
Pytorch à C++ : done,des5, 2021-10-01,2021-12-01
Installation FMT debug : done,des6, 2021-12-01,2022-03-01
Implémentation : done,des8, 2021-12-01,2022-03-01
Écriture de l'article estimateur de carbone :des16,2022-09-01,2023-04-01
Test et validation avec modèles réels :active,des15,2022-10-01,2023-05-01
section IA Planification spatiale
Test et extension à la planification référencée : done,des9, 2022-02-01,2022-05-01
Mise en place d'un plan : done,des10, 2021-12-01,2022-02-01
Lien FMT avec Python avec exemple : done,des11, 2022-01-01,2022-04-01
Modèle IA de spatialisation mimétique: done,des12, 2022-04-01,2022-10-01
Modèle IA d'évaluation de planification spatialisée :crit,des13,2022-09-01,2023-03-01
Modèle IA de spatialisation (avec carbone) :crit,des14,2023-02-01,2023-08-01
Écriture de l'article planification forestière :des17,2023-04-01,2023-08-01
Résultats concrets de la phase 1
- Nouvelle syntaxe pour la section yield
- Voir dans examples/Models/TWD_land/Scenarios/Predictors
- Développement d’un nouveau type de yield “*YM”
Nouvelle syntaxe Yields
{
Intrants:
- GFI = Volume de feuillus intolérants
- GFT = Volume de feuillus tolérants
- GF = Volume feuillu total
- GR = Volume résineux total
}
*YM ? ? ?
NEP _PRED(nep_carbon,GFI,GFT,GF,GR)
{
Extrants:
- AG_Biomass_C = Biomasse aérienne
- BG_Biomass_C = Biomasse souterraine
- Deadwood_C = Bois mort
- Litter_C = Littière
- Soil_C = Sol
}
Nouvelle Syntaxe Outputs
;Inventaire de la productivité nette de l'écosystème en (c)
*OUTPUT NEP_Total
*SOURCE ? ? ? _INVENT NEP
;Inventaire de la biomasse anérienne et souterraine en (c)
*OUTPUT Biomasse_Total
*SOURCE ? ? ? _INVENT AG_Biomass_C + ? ? ? _INVENT BG_Biomass_C
;Inventaire du carbone du sol en (c)
*OUTPUT Sols_Total
*SOURCE ? ? ? _INVENT Soil_C
gantt
dateFormat YYYY-MM-DD
tickInterval month
axisFormat %b%d
title Validation
excludes weekends
section Échelle Globale
Apprentissage (29 UA) :done,des1,2023-01-09,2023-01-23
Tests avec spatialisation : done,des2,2023-03-01,2023-04-01
Analyse des résultats : done,des3,2023-04-01,2023-04-17
Présentation : active,des4,2023-05-01,2023-05-02
section Échelle des régions écologiques
Apprentissage (29 UA) :done,des5,2023-01-02,2023-01-16
Tester l'IA (08665) : done,des6,2023-03-06,2023-03-27
section Optimisation du NEP
Tester avec 02751 : done,des7,2023-04-03,2023-04-24
GCBM vs IA (02751)
- Les modèles d’IA testés
- Région écologique trois modèles (Pessière,Sapinière,Érablière) entrainés avec calcul-2328
- Global un modèle entrainé avec calcul-2328
- Les types de modélisations
- Spatial (cellules de 14 ha)
- Non spatial (à l’échelle de la strate)
- Notre référence GCBM
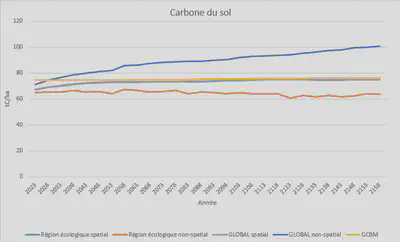
GCBM vs IA (02751)
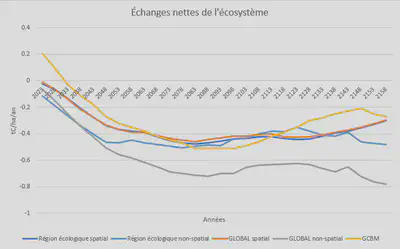
GCBM vs IA (02751)
Constats IA vs GCBM
- Le modèle d’IA par région écologique performe moins bien
- Sous estime le carbone des réservoirs
- À le plus grand écart avec le bilan des émissions nettes de GCBM
- Le modèle d’IA Global est le meilleur
- Les scénarios spatialement explicites se collent à GCBM
- Les scénarios non spatiaux performent moins bien
- L’objetif du projet était l’utilisation avec des modèles spatialement explicites
Pourquoi ces différences?
- Les résultats de l’IA diffèrent de GCBM car:
- L’IA suppose le feu comme perturbation historique
- GCBM utilise plus d’intrants
- Température annuelle moyenne
- Précipitations
- Transitions après perturbation
- Le modèle par région écologique performe moins bien car:
- Manque de données par modèle
- Les régions écologiques sont difficiles à identifier dans les modèles
- Superficie orphelines dans les modèles
Optimisation du NEP (02751)
- Les scénarios sont non spatiaux
- MAX_OVOLTOTREC: Détermination
- MAX_OAAM: Optimisation de l’accroissement annuel moyen
- MAX_NEP_GLOBAL: Optimisation du bilan (IA)
Optimisation du NEP (02751)
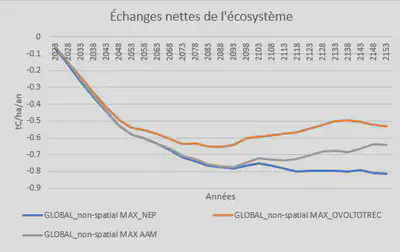
Constats
- Le scénario MAX NEP a le meilleur bilan carbone
- Le scénario MAX AAM stock plus de carbone dans les différents réservoirs
Conclusion
- On peut maintenant obtenir un bilan de carbone facilement pour:
- Une solution spatiale explicite et spatialement référencée
- Les cinq principaux réservoirs de l’écosystème
- Les émissions nettes de l’écosystème
- On peut maintenant utiliser le Machine Learning pour:
- Générer des intrants au calcul (Courbes de production, Paramètres économiques)
- La génération de solution spatiale avec IA:
- Nous permettra de faire de l’optimisation spatialement explicite
- Utilisation du projet de fin d’étude à B. Forest
- Replanification spatialement explicite
Les prochaines étapes
- Validation de l’impact de l’optimisation du NEP sur
- Le choix des travaux sylvicoles
- La productivité
- Les rotations
- Faire d’autres analyses (UA du sud)
- Faire un scénario de maximisation des puits de carbone
- Générer une base de donnée contenant les actions:
- Feux
- Récupération après feux
- Tester le tout en replanification
Des Questions?